配置Springboot/Nginx服务以便于监控服务状态
要点:本文旨在记录如何通过Grafana+Prometheus 监控K8S内部署的无公网域名服务的健康状态。Grafana作为一个展示平台,其更多用于数据展示分析汇总,数据来源于Prometheus,因此,Prometheus在监测链路中才是最主要的负责Scrap服务状态数据的服务。在各大论坛博客出处,已有如何通过配置Grafana+Prometheus来获取服务状态,但鲜有人讲述如何配置服务以便于Prometheus去抓取数据。因此,本文重点在于讲述如何通过配置Springboot服务和Nginx服务暴露其Metric监控数据接口,以供Prometheus调用消费。
一言蔽之,Prometheus即便已知如何Scrap数据,当被监测方不去提供数据接口,其仍旧无意义,即单相思总是不行的。
前言
随着云部署的发展,现在越来越多服务部署在云服务上,比如AWS、阿里云等等。而其部署平台核心大多都与K8S有关。
一个服务的健康与否,应当能及时给予监测结果。
试想以下情况,一名开发人员只注重业务代码开发,从未考虑服务健康状态如何监测,那一旦服务出现任何问题,都将致使服务无效,更别说去定位业务代码的问题。
因此,我们能知道,监测服务健康状态是具有十分重要意义的。
公有域名监测
一般来说,当我们服务部署后,拥有公网域名,可以通过Pingdom平台去监测轮询监测服务健康状态,其原理在于轮询所部属服务的某个API接口并判断返回状态码。
BTW,对于SpringBoot服务,框架可以通过配置文件暴露出health check endpoint以供监测平台进行查询。而其他框架的服务,若不自带健康监测endpoint,也可以通过自定义一个endpoint用于监测。
但有时我们需要监测部署在云平台上却又没有公网域名的服务,应该怎么做呢?
对于K8S而言,其可以通过部署Grafana+Prometheus方式直接监测服务的具体状态。
具体监控数据由被监测服务决定,其实很多状态数据都由框架生成,当然也可自定义。
K8S服务监控可阅读此文: K8S监控简介
了解K8S监控基本原理后,接下来将进入正题:
在各大论坛博客出处,已有如何通过配置Grafana+Prometheus来获取服务状态,随手一搜便是许多。
但是本文不去讲上游端如何抓取数据,而是分析下游端如何暴露数据以供抓取,
这便是本文主题:如何配置Springboot 服务和Nginx服务以供Prometheus监控健康状态。
Springboot 服务
目前而言,大部分后端服务都采用了Springboot框架,因此,了解如何配置暴露Springboot服务的健康监测端口十分必要。
正因为框架帮助开发人员封装了很多方法,对于Springboot服务,其已经具有了很多健康监测接口,比如health、info、metrics。主要依靠Springboot Actuator。
具体了解Springboot Actuator 可查看使用 Spring Boot Actuator 监控应用
了解基本概念后,可以查看如何简单配置使用Actuator。
若需要暴露某些Actuator接口以便于使用,可在*.properties文件增加以下配置:
# expose Actuator endpoint for prometheus
# base-path default is /actuator
management.endpoints.web.base-path=/custom-prefix
# exposure include `/health` `metrics` `/prometheus`
management.endpoints.web.exposure.include=health,metrics,prometheus此处需注意:若要修改base-path,就要使用第一个属性,若要暴露任何已定义Actuator接口,则在第二个属性后新增即可。
这里最主要的是增加了prometheus接口。其可将Actuator的/metrics(报告各种应用程序度量信息)的数据汇总成prome可识别的格式暴露在/prometheus接口。
若要使用/prometheus接口,还需要再Springboot服务中引入一个Library,具体添加方式为:在build.gradle.kts文件内的dependencies增加新依赖。
implementation("io.micrometer:micrometer-registry-prometheus:1.7.0")
// 注意:这是kotlin的gradle文件写法,如果是groove的gradle文件请自行更改符号格式。如果从来不了解gradle的DSL语法,请上网查阅至此,当在本地启动服务后,打开localhost:8080/custom-prefix/prometheus便能看到相关的metrics数据。当然其他接口下也有相应数据。
NOTE 引用:使用 Spring Boot Actuator 监控应用
HTTP 方法 路径 描述 GET /auditevents 显示应用暴露的审计事件 (比如认证进入、订单失败) GET /beans 描述应用程序上下文里全部的 Bean,以及它们的关系 GET /conditions 就是 1.0 的 /autoconfig ,提供一份自动配置生效的条件情况,记录哪些自动配置条件通过了,哪些没通过 GET /configprops 描述配置属性(包含默认值)如何注入Bean GET /env 获取全部环境属性 GET /env/{name} 根据名称获取特定的环境属性值 GET /flyway 提供一份 Flyway 数据库迁移信息 GET /liquidbase 显示Liquibase 数据库迁移的纤细信息 GET /health 报告应用程序的健康指标,这些值由 HealthIndicator 的实现类提供 GET /heapdump dump 一份应用的 JVM 堆信息 GET /httptrace 显示HTTP足迹,最近100个HTTP request/repsponse GET /info 获取应用程序的定制信息,这些信息由info打头的属性提供 GET /logfile 返回log file中的内容(如果 logging.file 或者 logging.path 被设置) GET /loggers 显示和修改配置的loggers GET /metrics 报告各种应用程序度量信息,比如内存用量和HTTP请求计数 GET /metrics/{name} 报告指定名称的应用程序度量值 GET /scheduledtasks 展示应用中的定时任务信息 GET /sessions 如果我们使用了 Spring Session 展示应用中的 HTTP sessions 信息 POST /shutdown 关闭应用程序,要求endpoints.shutdown.enabled设置为true GET /mappings 描述全部的 URI路径,以及它们和控制器(包含Actuator端点)的映射关系 GET /threaddump 获取线程活动的快照
可能看到这里,读者要说,这不都是基操,有何必要再写出来,随便一篇博客都比这份清晰深入。
但是其实希望自己明白,因此梳理一遍最近所遇相关问题,其次便于之后再遇到相似问题查找方便,最后,也会附上Springboot如何注册自定义Metrics数据的方法。
自定义Metrics数据
正如之前所说,部分情况下,我们需要监测内部服务的健康状态,此时,并不需要过多的数据描述,只需要一个合适的metric作为服务健康与否的指标即可。但是当配置完服务的actuator和/proemtheus后,发现其内更多的是JVM的相关数据,并没有一个明确的指标作为数据源。
此时,我们回想之前所说,Springboot 已经配置了health check endpoint,那么,是否可以通过自定义metric将health check结果注册进MeterRegistry内进而实现将数据暴露在/prometheus接口内呢?答案当然是肯定的
Springboot MeterRegistry 相关可查看:JVM应用度量框架Micrometer
思路及方法参考Stack Overflow论坛。
...
// 使用MeterRegistry 注册自定义的 gauge(量值)类型数据,将定期轮询health check endpoint结果并将值赋给自定义指标
// 服务的health check的结果来源于Springboot容器内的HealthEndpoint bean。
@Configuration
class MyHealthMetricsConfig(customerMeterRegistry: MeterRegistry) {
@Autowired
private lateinit var myHealthEndpoint: HealthEndpoint
private val myHealthCheck: AtomicInteger? = customerMeterRegistry.gauge("health_check", AtomicInteger(0))
@Scheduled(fixedRateString = "60000", initialDelayString = "10000")
fun schedulingTask() {
myHealthCheck!!.set(myHealthToCode(myHealthEndpoint))
}
companion object {
private fun myHealthToCode(endPoint: HealthEndpoint): Int {
// 监测服务healthc 端点的的结果状态,up 为1 ,非up 均为0。 以数值结果代表服务健康状态
return if (endPoint.health().status == Status.UP) 1 else 0
}
}
}至此,可以在/promtheus接口查询到命名为health_check的数据结果。如何去使用数据便在消费端去自定义了。
此方法不仅可用于定义一个健康监测指标,若有任何其他需要自定义的指标数据,也可使用此部分代码套路进行声明、注册、赋值操作。
后端Springboot服务具体配置已梳理完结,若之后有新增信息,会进行补充说明。
之后会进行前端Nginx配置简单分析,因Nginx是个中间件,不像框架已做一部分工作,因此还需一些新引入配置,接下来我们来看具体如何配置Nginx已暴露数据供监测方使用。
Nginx 服务
前端大部分服务都是已打包完成的html/css/js文件,实际部署时,只是将相应的文件放在Nginx服务器上,并对Nginx服务进行简单配置即可。因此前端服务的监测主要集中在监测Nginx服务数据状态,而Nginx服务作为代理中间件,其内会接受发送大量的Http请求,因此通过监测Http请求的一些数据,便可实现对部署在Nginx上的服务状态进行监测。
如上所述,Nginx与Springboot不同,并不能通过简单配置便可是Prome直接获取到Nginx相关的服务状态数据。但,车到山前必有路,已有很多服务可以作为Nginx和Prometheus通信的桥梁,实现将Nginx数据汇总整理暴露成metric结果形式的数据供Prometheus消费。
常用的有两种:
- NGINX Prometheus Exporter: NGINX exposes a handful of metrics via the stub_status page
- NGINX-to-Prometheus log file exporter: Helper tool that continuously reads an NGINX log file (or any kind of similar log file) and exports metrics to Prometheus.
具体如何配置以实现桥梁作用,和已定义的metric可直接查看其Github的主页README文档,十分详细,此处不再阐述基本概念内容。
接下来进行一个Demo实现描述具体如何配置
Demo示例:描述如何使用NGINX-to-Prometheus log file exporter 实现step by step完成监测Nginx服务健康状态的配置。
下图简单展示了Nginx 和 Prometheus_nignxlog_exporter 以及 Prometheus 和 Grafana的 关系。
由 Prometheus_nignxlog_exporter服务的作用可知,其主要作为Nginx和Prometheus的中间桥梁,主要通过收集Nginx的log日志,进而整理出一份关于Nginx服务的监控指标数据结果,并将结果暴露给Prometheus使用。具体指标可查Github文档。
任何事务的协作都需双方同意,因此,在使用Prometheus_nignxlog_exporter时需要配置Nginx服务保证将log日志输出至某个位置,比如将log输出至<IP>:<PORT>。同时配置Prometheus_nignxlog_exporter的监听地址。即可实现nignxlog_exporter获取Nginx log进而依据日志整理Nginx服务的状态数据。同样,Prometheus如何获取Nginx服务的状态数据,即通过监听Prometheus_nignxlog_exporter的某个暴露地址,通过配置轮询收集状态数据。
至于Prometheus和Grafana,不是此文重点,不再阐述。
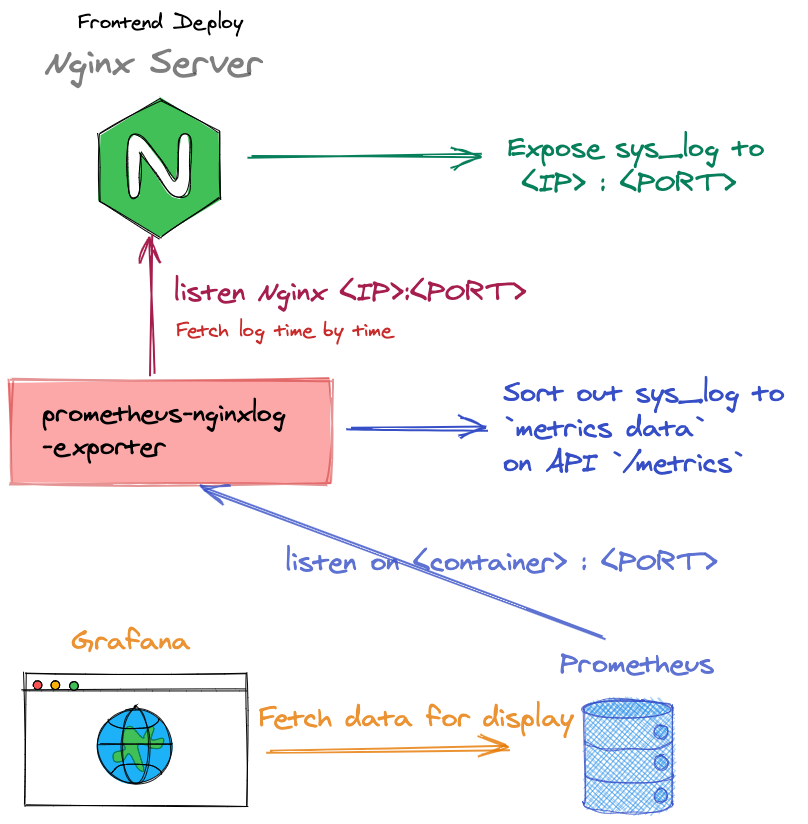
经过简单的梳理,相信读者老爷们已经有一定了解,具体配置可归纳为以下几步:
- 在Nginx conf 文件中,增加相关log format定义和log 输出地址
- 在服务中新增prometheus_nginxlog_exporter容器,并设置其expose数据指标的Port和API地址(API 默认为
/metrics) - 设置prometheus_nginxlog_exporter的配置文件,主要设置source logs的
<IP>:<PORT>和其他针对数据的处理。 - 配置Prometheus以抓取prometheus_nginxlog_exporter数据指标,根据其第二步expose的Port和API地址设置。
- 配置Grafana以根据具体metric选择展示的数据。
接下来,通过一部分代码展示如何配置Nginx和prometheus_nginxlog_exporter。
Nginx 配置
在Nginx配置文件中新增log format格式和access_log参数
log_format prometheus_exporter_log_format '$remote_addr - $remote_user [$time_local] '
'"$request_uri" $request_time $status';
access_log syslog:server=127.0.0.1:88888 prometheus_exporter_log_format;定义一个prometheus_exporter_log_format代表log格式。使用access_log输出system logs至127.0.0.1:88888,其log格式依照prometheus_exporter_log_format定义。
prometheus_nginxlog_exporter 配置
Nginx已将logs输出,因此需要增加相关配置文件,此处不展示如何在一个服务内启动一个prometheus_nginxlog_exporter。
简易版配置如下:
listen:
port: 4040
# metrics_endpoint 默认为 "/metrics"
metrics_endpoint: "/api/nginx/metrics"
enable_experimental: true
namespaces:
# metrics前缀, for example `my_nginx_app_<固定metric名>`
- name: my_nginx_app
format: '$remote_addr - $remote_user [$time_local] ' '\"$request_uri\" $request_time $status';
# 设置所抓取 nignx 服务 logs 具体地址
source:
syslog:
listen_address: "udp://127.0.0.1:88888"
# format 格式代码rfc3164,可查询https://www.diaryfolio.com/2020/07/syslog-standards-simple-comparison.html查看相关
format: rfc3164
tags:
- nginx
labels:
app: my_nginx_app
nginx: nginx
# relabel的配置
relabel_configs:
# 对 request_uri 的 path label的内容进行查询替换操作等
- target_label: path
from: request_uri
matches:
# 去除 path中 URL 查询参数
- regexp: '^([^?]*)?.*'
replacement: '$1'注意:在配置prometheus_nginxlog_exporter时,可能需要将配置文件挂载在某volume上以便于服务启动使用。
当然这时候还存在一个问题,Nginx服务如何能规律的产生log呢?
这就需要引入k8s的liveness和readiness probe监测配置了。
K8S 容器状态监测
Both liveness & readiness probes are used to control the health of an application. Failing liveness probe will restart the container, whereas failing readiness probe will stop our application from serving traffic.
Refer: Liveness and Readiness Probes — Difference
至此,一个如何配置Nginx 前端服务的监控数据指标讲解完成。
结语
正如前言所说,本文仅针对Dev如何配置所开发的服务的以暴露监控指标便于监控平台识别,具体监控平台方如何配置,如何告警不在本文范畴。
希望通过本文讲述如何通过配置Springboot服务和Nginx服务暴露其Metric监控数据接口,以供Prometheus调用消费。能让读者有所启发或思路进行扩展。
当然,本文也只是在结合作者个人使用经验进行整理和记录,奈何作者经验浅薄,又不愿将来有用之时却寻找不到相关资料,故而书写此文。
必然文中有些文字不恰当或错误之处,若读者不介意,请一一指出。



